Prediction of metabolites by MicrobeRX
Loading the modules and data files of MicrobeRX
MicrobeRX requires a database of reaction rules in order to predict. The program can only make predictions based on reaction rules; however, evidences of human and gut microbial biotransoformations have been included to help identify the origin of the metabolites.
Load the DataFiles module to load the evidences and reaction rules.
[1]:
from microberx.DataFiles import load_evidences, load_reaction_rules
import pandas as pd
The reaction rules and evidences are easily accessible as dataframes. Use these files as templates if you want to make predictions based on your own rules and evidences. MicrobeRX’s functionality is dependent on these files.
[2]:
EVIDENCES= load_evidences()
EVIDENCES.head(5)
INFO: Loading evidences...
[2]:
| reaction_id | compartment | origin | name | subsystem | scheme_ids | scheme_names | reversibility | ec | metanetx_reaction | seed_reaction | sbo | rhea | kegg_reaction | pubmed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 23DHMPO | Cytosol | GutMicrobes | (R)-2,3-Dihydroxy-3-methylpentanoate:NADP+ oxi... | Valine, leucine, and isoleucine metabolism | 23dhmp[c] + nadp[c] <=> 3h3mop[c] + h[c] + nad... | (R)-2,3-Dihydroxy-3-methylpentanoate + Nicotin... | True | 1.1.1.86 | MNXR188296 | rxn03435 | SBO:0000176 | NaN | NaN | NaN |
| 1 | 26DAPLLAT | Cytosol | GutMicrobes | L,L-diaminopimelate aminotransferase | Lysine metabolism | 26dap_LL[c] + akg[c] <=> glu_L[c] + h2o[c] + h... | LL-2,6-Diaminoheptanedioate + 2-Oxoglutarate <... | True | 2.6.1.83 | MNXR97144 | rxn07441 | SBO:0000176 | NaN | NaN | NaN |
| 2 | 2AHBUTI | Cytosol | GutMicrobes | (S)-2-Aceto-2-hydroxybutanoate isomerase | Valine, leucine, and isoleucine metabolism | 2ahbut[c] <=> 3h3mop[c] | (S)-2-Aceto-2-hydroxybutanoate <=> (R)-3-Hydro... | True | 1.1.1.86;5.4.99.3 | MNXR191966 | rxn03436 | SBO:0000176 | NaN | NaN | NaN |
| 3 | 3MOBS | Cytosol | GutMicrobes | 3-methyl-2-oxobutanoate synthase | Valine, leucine, and isoleucine metabolism | 3c3hmp[c] + coa[c] + h[c] <=> 3mob[c] + accoa[... | 3-Carboxy-3-hydroxy-4-methylpentanoate + Coenz... | True | 2.3.3.13;4.1.3.12 | MNXR188277 | rxn00902 | SBO:0000176 | NaN | NaN | NaN |
| 4 | 3OAR120 | Cytosol | GutMicrobes | 3-oxoacyl-[acyl-carrier-protein] reductase (n-... | Fatty acid synthesis | 3oddecACP[c] + h[c] + nadph[c] <=> 3hddecACP[c... | 3-Oxododecanoyl-[acyl-carrier protein] + proto... | True | 1.1.1.100 | MNXR152659 | rxn05340 | SBO:0000176 | NaN | NaN | NaN |
[3]:
RULES_DATABASE = load_reaction_rules()
RULES_DATABASE.head(5)
INFO: Loading reaction rules...
[3]:
| num_atoms | rule | substrate | substrate_map | product | product_map | reaction_id | |
|---|---|---|---|---|---|---|---|
| 0 | 4 | [#6&!R:3]-[#6&!R:6](-[#8&!R:7])-[#6&!R:8]>>[#6... | 23dhmp | [CH3:1][CH2:2][C:3]([CH3:4])([OH:5])[CH:6]([OH... | 3h3mop | [CH3:1][CH2:2][C:3]([CH3:4])([OH:5])[C:6](=[O:... | 23DHMPO_LR |
| 1 | 9 | [#6&!R:2]-[#6&!R:3](-[#6&!R:4])(-[#8&!R:5])-[#... | 23dhmp | [CH3:1][CH2:2][C:3]([CH3:4])([OH:5])[CH:6]([OH... | 3h3mop | [CH3:1][CH2:2][C:3]([CH3:4])([OH:5])[C:6](=[O:... | 23DHMPO_LR |
| 2 | 10 | [#6&!R:1]-[#6&!R:2]-[#6&!R:3](-[#6&!R:4])(-[#8... | 23dhmp | [CH3:1][CH2:2][C:3]([CH3:4])([OH:5])[CH:6]([OH... | 3h3mop | [CH3:1][CH2:2][C:3]([CH3:4])([OH:5])[C:6](=[O:... | 23DHMPO_LR |
| 3 | 4 | [#6&!R:3]-[#6&!R:6](=[#8&!R:7])-[#6&!R:8]>>[#6... | 3h3mop | [CH3:1][CH2:2][C:3]([CH3:4])([OH:5])[C:6](=[O:... | 23dhmp | [CH3:1][CH2:2][C:3]([CH3:4])([OH:5])[CH:6]([OH... | 23DHMPO_RL |
| 4 | 9 | [#6&!R:2]-[#6&!R:3](-[#6&!R:4])(-[#8&!R:5])-[#... | 3h3mop | [CH3:1][CH2:2][C:3]([CH3:4])([OH:5])[C:6](=[O:... | 23dhmp | [CH3:1][CH2:2][C:3]([CH3:4])([OH:5])[CH:6]([OH... | 23DHMPO_RL |
Prediction of metabolites
Aside from rules, the query molecule is an important component for prediction. Because the program uses rdkit to handle molecules, the queries can be represented in a variety of formats. For instance, SMILE, SMARTS, InChi, and so on.
Importing the prediction module of MicrobeRX
[4]:
from microberx import MetabolitePredictor
[5]:
from rdkit import Chem
smi="[H][C@@]12CC[C@](O)(C(=O)CO)[C@@]1(C)CC(=O)[C@@]1([H])[C@@]2([H])CCC2=CC(=O)C=C[C@]12C"
query_name='Prednisone'
query=Chem.MolFromSmiles(smi)
query
[5]:
Predictions can take from a few seconds to a few minutes, depending on the number of reaction rules used. For clarity, the program will display a progress bar.
[6]:
Predictor=MetabolitePredictor(query,query_name=query_name,biosystem="all",cut_off=0.6)
Predictor.run_prediction()
INFO: Loading evidences...
INFO: Loading reaction rules...
The prediction module’s main output is a dataframe containing detailed information about the rules used and the prediction performed. The main data is a column containing the predicted metabolite structures as SMILES (main product smiles) along with other relevant information. It is recommended that you explore the dataframe to become acquainted with this output.
[7]:
metabolites=Predictor.predicted_metabolites
metabolites.head(5)
[7]:
| main_product_smiles | secondary_products_smiles | similarity_substrates | similarity_products | reacting_atoms_in_query | reaction_id | substrate | product | num_atoms | bigg_reaction | ... | compartment | name | subsystem | reversibility | ec | metanetx_reaction | seed_reaction | rhea | kegg_reaction | pubmed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CC12C=CC(=O)C=C1CCC1C2C(O)CC2(C)C1CCC2(O)C(=O)CO | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.867 | 0.868 | [24, 18, 17, 16, 15, 14, 12, 13, 11, 9, 10, 0,... | HSD11B1r_LR | cortsn | crtsl | 15 | HSD11B1r | ... | Endoplasmic_reticulum | 11-Beta-Hydroxysteroid Dehydrogenase Type 1 | Steroid metabolism | 1.1.1.146 | MNXR145242 | 11673786;15466942;7859916 | ||||
| 1 | CC12C=CC(=O)C=C1CCC1C2C(O)CC2(C)C1CCC2(O)C(=O)CO | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.867 | 0.868 | [24, 18, 17, 16, 15, 14, 12, 13, 11, 9, 10, 0,... | HSD11B2r_LR | cortsn | crtsl | 15 | HSD11B2r | ... | Endoplasmic_reticulum | 11-Beta-Hydroxysteroid Dehydrogenase Type 2 | Steroid metabolism | 1.1.1.27 | MNXR145244 | 11673786;15466942;7859916 | ||||
| 2 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C1CCC2(O)C(=O... | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.741 | 0.752 | [24, 18, 17, 16, 15, 14, 12, 11, 9, 10, 0, 1, ... | HMR_1988_LR | 17ahprgstrn | 11docrtsl | 18 | HMR_1988 | ... | Cytosol | Steroid 21-Monooxygenase | Steroid metabolism | 1.14.99.10 | MNXR102263 | 3487786;3038528 | ||||
| 3 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C1CCC2(O)C(=O... | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.741 | 0.752 | [24, 18, 17, 16, 15, 14, 12, 11, 9, 10, 0, 1, ... | P45021A2r_LR | 17ahprgstrn | 11docrtsl | 18 | P45021A2r | ... | Endoplasmic_reticulum | Steroid 21-Hydroxylase | Steroid metabolism | 1.14.99.10 | MNXR102263 | 16541276;18381579;18381580 | ||||
| 4 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C(=O)CCC12 | O=C([O-])CO.NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])... | 0.741 | 0.705 | [10, 9, 11, 12, 14, 15, 16, 17, 18, 24, 0, 1, ... | RE1096M_LR | 17ahprgstrn | andrstndn | 18 | RE1096M | ... | Mitochondria | RE1096M | Steroid metabolism | 2.4.1.17 | MNXR102258 | 10049998;7578007 |
5 rows × 24 columns
[ ]:
#metabolites.to_csv('test/prednisone_metabolites.tsv',sep='\t',index=False)
Analysis and Visualization
The ability to predict chemical structures is at the heart of MicrobeRX. As a result, the tool includes a number of fuctions for analyzing and visualizing the predicted metabolites.
The following sequence presents a possible analysis idea. However, the user can use the functions in any order that best suits their needs.
Along with the DataFiles, MicrobeRX includes a number of tools for analyzing and visualizing metabolites and evidences.
Analyzer:
compute_molecular_descriptors
compute_isotopic_mass
search_pubchem
classify_molecules
Visualizer:
plot_confidence_scores
plot_molecular_descriptors
plot_isotopic_masses
plot_metabolic_accesibility
display_molecules
plot_evidences
[8]:
from microberx.MetaboliteAnalyzer import compute_molecular_descriptors, compute_isotopic_mass, search_pubchem, classify_molecules
from microberx.MetaboliteVisualizer import plot_confidence_scores, plot_molecular_descriptors, plot_boiled_egg, plot_isotopic_masses, plot_metabolic_accesibility, display_molecules, plot_relationships
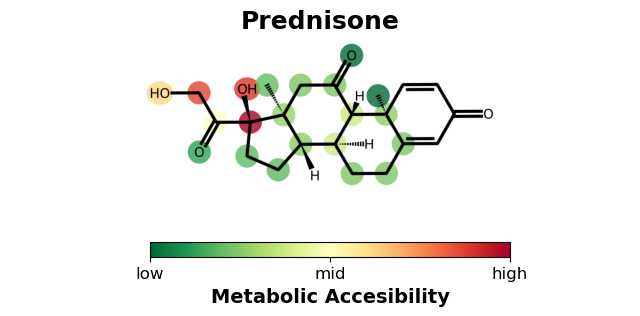
Metabolic accesibility
This function creates a 2D image of a molecule with the atoms colored according to their metabolic accessibility, which is calculated as the frequency of the atom in the reacting_atoms_in_query column of the data frame. The function returns a matplotlib Figure object that can be displayed or modified.
[9]:
accesibility=plot_metabolic_accesibility(metabolites,molecule=query,atom_map_col='reacting_atoms_in_query',mol_name=query_name,alpha=0.8)
Confidence score
This function creates a 3D scatter plot of the data frame with the x, y, and z axes representing the similarity of substrates, products, and reacting atoms efficiency respectively. The color of each point indicates the confidence score of the corresponding metabolite id. The function returns an interactive plotly Figure object that can be displayed or modified.
[10]:
plot_confidence_scores(metabolites)
Results manipulation
Because of the number of atoms used in reaction rules during the predictions. Predictions with varying levels of structural confidence can be obtained. The benefit of using data frames is that filtering and selecting results is very simple.
[11]:
best_metabolites=metabolites[metabolites.confidence_score>=1.5]
[12]:
unique_metabolites=best_metabolites.drop_duplicates(subset=['metabolite_id'],ignore_index=True)
Plot relationships
This function generates a Sankey diagram to display the relationships between metabolite annotations in a data frame. This plot is especially interesting for analyzing the relationships between metabolites and evidences.
The use of standardized Recon3D and AGORA2 reactions enables the use of high-quality annotations of the biotransformations included in MicrobeRX. The following example provides an interesting and straightforward analysis of the relationships between predicted metabolites and the enzymes and organisms that produce them.
[15]:
plot_relationships(unique_metabolites,nodes=["reaction_id","origin","compartment","subsystem","name",'metabolite_id'])
Molecular descriptors
This function computes and plots common molecular descriptors for a given data frame using SMILES strings. The descriptors are added as new columns at the end of the dataframe.
Lipinski and Veber columns indicates whether the molecule satisfies the Lipinski’s or Veber’s rules or not for easy identification of orally active drugs.
Moreover, Brenk and PAINS matches are listed for the identification of unwanted reactive substructures or pan-assay interference compounds.
[16]:
descriptors=compute_molecular_descriptors(unique_metabolites,smiles_col='main_product_smiles')
descriptors.head()
[16]:
| main_product_smiles | secondary_products_smiles | similarity_substrates | similarity_products | reacting_atoms_in_query | reaction_id | substrate | product | num_atoms | bigg_reaction | ... | MolWt | LogP | NumHAcceptors | NumHDonors | NumRotatableBonds | TPSA | MolFormula | Lipinski | Veber | Brenk | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CC12C=CC(=O)C=C1CCC1C2C(O)CC2(C)C1CCC2(O)C(=O)CO | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.867 | 0.868 | [24, 18, 17, 16, 15, 14, 12, 13, 11, 9, 10, 0,... | HSD11B1r_LR | cortsn | crtsl | 15 | HSD11B1r | ... | 360.450 | 1.558 | 5.0 | 3.0 | 2.0 | 94.83 | C21H28O5 | True | True | nan |
| 1 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C1CCC2(O)C(=O... | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.741 | 0.752 | [24, 18, 17, 16, 15, 14, 12, 11, 9, 10, 0, 1, ... | HMR_1988_LR | 17ahprgstrn | 11docrtsl | 18 | HMR_1988 | ... | 374.433 | 1.084 | 6.0 | 3.0 | 2.0 | 111.90 | C21H26O6 | True | True | het-C-het_not_in_ring |
| 2 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C(=O)CCC12 | O=C([O-])CO.NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])... | 0.741 | 0.705 | [10, 9, 11, 12, 14, 15, 16, 17, 18, 24, 0, 1, ... | RE1096M_LR | 17ahprgstrn | andrstndn | 18 | RE1096M | ... | 298.382 | 3.042 | 3.0 | 0.0 | 0.0 | 51.21 | C19H22O3 | True | True | nan |
| 3 | CC(=O)OCC(=O)C1(O)CCC2C3CCC4=CC(=O)C=CC4(C)C3C... | CC(C)(COP(=O)([O-])OP(=O)([O-])OCC1OC(N2CNc3c(... | 0.729 | 0.761 | [8, 7, 5, 6, 3, 4, 2, 1, 0, 15, 14, 12, 11, 9,... | ACCOACORAT_LR | crtsl | hcsnact | 15 | ACCOACORAT | ... | 400.471 | 2.337 | 6.0 | 1.0 | 3.0 | 97.74 | C23H28O6 | True | True | nan |
| 4 | CC(=O)C1(O)CCC2C3CCC4=CC(=O)C=CC4(C)C3C(=O)CC21C | O=O.NC(=O)C1=CN(C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.729 | 0.707 | [7, 5, 6, 3, 4, 2, 1, 0, 15, 14, 12, 11, 9, 10] | HMR_1990_LR | crtsl | M00603 | 15 | HMR_1990 | ... | 342.435 | 2.793 | 4.0 | 1.0 | 1.0 | 71.44 | C21H26O4 | True | True | nan |
5 rows × 34 columns
The function normalizes the molecular descriptors to fit in the range [0, 1] and then plots them as radial lines for each compound. The function also plots the upper and lower limits of the Lipinski’s rule of five as shaded regions in orange and yellow, respectively. The function uses distinct colors for each compound and displays a legend on the right side of the plot.
[17]:
plot_molecular_descriptors(descriptors,names_col='metabolite_id')
Apart from efficacy and toxicity, many compounds have poor pharmacokinetics and bioavailability. Gastrointestinal absorption and brain access are two pharmacokinetic behaviors crucial to estimate at various stages of the drug discovery processes. To this end, the Brain Or IntestinaL EstimateD permeation method (BOILED-Egg) is proposed as an accurate predictive model that works by computing the lipophilicity and polarity of small molecules.
[18]:
plot_boiled_egg(descriptors,names_col='metabolite_id')
Isotopic masses
The function iterates over the rows of the data frame and uses the EmpiricalFormula class from pyOpenMS to create an object for each molecular formula. Then, it generates the isotopic mass distribution. It calculates the sum of the probabilities of all isotopes and stores it in the ‘probability_sum’ column. It also formats the mass and probability of each isotope as a string and stores it in the ‘mass_distribution’ column, separated by semicolons.
[19]:
masses=compute_isotopic_mass(descriptors,molformula_col='MolFormula')
masses.head()
[19]:
| main_product_smiles | secondary_products_smiles | similarity_substrates | similarity_products | reacting_atoms_in_query | reaction_id | substrate | product | num_atoms | bigg_reaction | ... | NumHAcceptors | NumHDonors | NumRotatableBonds | TPSA | MolFormula | Lipinski | Veber | Brenk | probability_sum | mass_distribution | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CC12C=CC(=O)C=C1CCC1C2C(O)CC2(C)C1CCC2(O)C(=O)CO | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.867 | 0.868 | [24, 18, 17, 16, 15, 14, 12, 13, 11, 9, 10, 0,... | HSD11B1r_LR | cortsn | crtsl | 15 | HSD11B1r | ... | 5.0 | 3.0 | 2.0 | 94.83 | C21H28O5 | True | True | nan | 1.0 | 360.1937:78.5875;361.197:18.2524;362.2004:2.83... |
| 1 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C1CCC2(O)C(=O... | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.741 | 0.752 | [24, 18, 17, 16, 15, 14, 12, 11, 9, 10, 0, 1, ... | HMR_1988_LR | 17ahprgstrn | 11docrtsl | 18 | HMR_1988 | ... | 6.0 | 3.0 | 2.0 | 111.90 | C21H26O6 | True | True | het-C-het_not_in_ring | 1.0 | 374.1729:78.4197;375.1763:18.2252;376.1797:2.9... |
| 2 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C(=O)CCC12 | O=C([O-])CO.NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])... | 0.741 | 0.705 | [10, 9, 11, 12, 14, 15, 16, 17, 18, 24, 0, 1, ... | RE1096M_LR | 17ahprgstrn | andrstndn | 18 | RE1096M | ... | 3.0 | 0.0 | 0.0 | 51.21 | C19H22O3 | True | True | nan | 1.0 | 298.1569:80.7305;299.1603:16.8865;300.1636:2.1... |
| 3 | CC(=O)OCC(=O)C1(O)CCC2C3CCC4=CC(=O)C=CC4(C)C3C... | CC(C)(COP(=O)([O-])OP(=O)([O-])OCC1OC(N2CNc3c(... | 0.729 | 0.761 | [8, 7, 5, 6, 3, 4, 2, 1, 0, 15, 14, 12, 11, 9,... | ACCOACORAT_LR | crtsl | hcsnact | 15 | ACCOACORAT | ... | 6.0 | 1.0 | 3.0 | 97.74 | C23H28O6 | True | True | nan | 1.0 | 400.1886:76.7392;401.1919:19.5123;402.1953:3.3... |
| 4 | CC(=O)C1(O)CCC2C3CCC4=CC(=O)C=CC4(C)C3C(=O)CC21C | O=O.NC(=O)C1=CN(C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.729 | 0.707 | [7, 5, 6, 3, 4, 2, 1, 0, 15, 14, 12, 11, 9, 10] | HMR_1990_LR | crtsl | M00603 | 15 | HMR_1990 | ... | 4.0 | 1.0 | 1.0 | 71.44 | C21H26O4 | True | True | nan | 1.0 | 342.1831:78.7921;343.1865:18.2518;344.1898:2.6... |
5 rows × 36 columns
This function plots the isotopic mass distribution of a given data frame using plotly.
[20]:
plot_isotopic_masses(masses,names_col='metabolite_id',mass_distribution_col='mass_distribution')
PubChem identifiers
The function iterates over the rows of the data frame and uses the pubchempy library to query the PubChem database for compounds that match the identifier in the specified column and namespace. It extracts the CIDs, SIDs and synonyms of the matching compounds and stores them in the corresponding columns of the data frame.
This function sends an online request to the PubChem server in order to conduct the search. When performing this task, make sure you have an internet connection. Metabolite annotation could be a time-consuming process. It is best not to conduct searches on large numbers of molecules.
[21]:
search_pubchem(masses,entry_col='main_product_smiles')
INFO: 'PUGREST.NotFound'
INFO: 'PUGREST.NotFound'
INFO: 'PUGREST.NotFound'
INFO: 'PUGREST.NotFound'
INFO: 'PUGREST.NotFound'
INFO: 'PUGREST.NotFound'
[21]:
| main_product_smiles | secondary_products_smiles | similarity_substrates | similarity_products | reacting_atoms_in_query | reaction_id | substrate | product | num_atoms | bigg_reaction | ... | TPSA | MolFormula | Lipinski | Veber | Brenk | probability_sum | mass_distribution | PubChem_CID | PubChem_SID | PubChem_Synonyms | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CC12C=CC(=O)C=C1CCC1C2C(O)CC2(C)C1CCC2(O)C(=O)CO | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.867 | 0.868 | [24, 18, 17, 16, 15, 14, 12, 13, 11, 9, 10, 0,... | HSD11B1r_LR | cortsn | crtsl | 15 | HSD11B1r | ... | 94.83 | C21H28O5 | True | True | nan | 1.0 | 360.1937:78.5875;361.197:18.2524;362.2004:2.83... | 4894 | 4500855;7996730;8153012 | 11,17,21-Trihydroxypregna-1,4-diene-3,20-dione... |
| 1 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C1CCC2(O)C(=O... | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.741 | 0.752 | [24, 18, 17, 16, 15, 14, 12, 11, 9, 10, 0, 1, ... | HMR_1988_LR | 17ahprgstrn | 11docrtsl | 18 | HMR_1988 | ... | 111.90 | C21H26O6 | True | True | het-C-het_not_in_ring | 1.0 | 374.1729:78.4197;375.1763:18.2252;376.1797:2.9... | 86210504 | ||
| 2 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C(=O)CCC12 | O=C([O-])CO.NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])... | 0.741 | 0.705 | [10, 9, 11, 12, 14, 15, 16, 17, 18, 24, 0, 1, ... | RE1096M_LR | 17ahprgstrn | andrstndn | 18 | RE1096M | ... | 51.21 | C19H22O3 | True | True | nan | 1.0 | 298.1569:80.7305;299.1603:16.8865;300.1636:2.1... | 522664 | 4479565;8672027;10535559 | MLS002694507;CHEMBL1877745;HMS3086E21;AKOS0243... |
| 3 | CC(=O)OCC(=O)C1(O)CCC2C3CCC4=CC(=O)C=CC4(C)C3C... | CC(C)(COP(=O)([O-])OP(=O)([O-])OCC1OC(N2CNc3c(... | 0.729 | 0.761 | [8, 7, 5, 6, 3, 4, 2, 1, 0, 15, 14, 12, 11, 9,... | ACCOACORAT_LR | crtsl | hcsnact | 15 | ACCOACORAT | ... | 97.74 | C23H28O6 | True | True | nan | 1.0 | 400.1886:76.7392;401.1919:19.5123;402.1953:3.3... | 539225 | 7698251;8675577;39364481 | MLS002638169;CHEMBL1715582;DTXSID10871607;HMS3... |
| 4 | CC(=O)C1(O)CCC2C3CCC4=CC(=O)C=CC4(C)C3C(=O)CC21C | O=O.NC(=O)C1=CN(C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.729 | 0.707 | [7, 5, 6, 3, 4, 2, 1, 0, 15, 14, 12, 11, 9, 10] | HMR_1990_LR | crtsl | M00603 | 15 | HMR_1990 | ... | 71.44 | C21H26O4 | True | True | nan | 1.0 | 342.1831:78.7921;343.1865:18.2518;344.1898:2.6... | 72395525 | ||
| 5 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C1CCC2(OC1OC(... | O=c1ccn(C2OC(COP(=O)([O-])OP(=O)([O-])[O-])C(O... | 0.581 | 0.771 | [24, 18, 17, 16, 15, 14, 12, 11, 9, 10, 3, 4, ... | UGT1A4r_LR | tststerone | tststeroneglc | 15 | UGT1A4r | ... | 190.72 | C27H33O11- | False | False | nan | 1.0 | 532.195:72.6296;533.1984:21.7896;534.2017:4.79... | None | ||
| 6 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C1CCC2(O)C(O)C=O | 0.578 | 0.596 | [24, 18, 17, 16, 15, 14, 12, 11, 9, 10, 3, 5, ... | DOCTNKI_LR | 11docrtstrn | M00041 | 18 | DOCTNKI | ... | 91.67 | C21H26O5 | True | True | aldehyde | 1.0 | 358.178:78.6055;359.1814:18.2385;360.1847:2.82... | 74066286 | |||
| 7 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C(C(=O)CO)CCC12 | O=O.NC(=O)C1=CN(C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.698 | 0.627 | [7, 5, 6, 3, 2, 1, 0, 15, 14, 12, 11, 9, 10] | HMR_1991_LR | M00603 | M00285 | 14 | HMR_1991 | ... | 71.44 | C21H26O4 | True | True | nan | 1.0 | 342.1831:78.7921;343.1865:18.2518;344.1898:2.6... | 14754645 | 323233180;384695406;399024121 | SCHEMBL20827665 |
| 8 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C1CCC2(OS(=O)... | Nc1ncnc2-c1NCN2C1OC(COP(=O)([O-])[O-])C(OP(=O)... | 0.581 | 0.609 | [24, 18, 17, 16, 15, 14, 12, 11, 9, 10, 3, 4, ... | TSTSTERONESULT_LR | tststerone | tststerones | 15 | TSTSTERONESULT | ... | 135.04 | C21H26O8S | True | True | Sulfonic_acid_2 | 1.0 | 438.1348:74.23;439.1382:17.9023;440.1416:6.640... | None | ||
| 9 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C1CCC2(O)C(O)CO | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.518 | 0.571 | [7, 5, 6, 3, 2, 1, 0, 15, 16, 17, 18, 24, 14, ... | AKR1C1_LR | prgstrn | aprgstrn | 17 | AKR1C1 | ... | 94.83 | C21H28O5 | True | True | nan | 1.0 | 360.1937:78.5875;361.197:18.2524;362.2004:2.83... | 3382688 | 4502144;36229691;75263968 | AKOS024419641;FT-0670023;17-ALPHA,20-BETA,21-T... |
| 10 | CC12C=CC(=O)C=C1CC(O)C1C2C(=O)CC2(C)C1CCC2(O)C... | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.781 | 0.711 | [14, 15, 16, 17, 18, 24] | P45011B12m_LR | 11docrtsl | crtsl | 6 | P45011B12m | ... | 111.90 | C21H26O6 | True | True | nan | 1.0 | 374.1729:78.4197;375.1763:18.2252;376.1797:2.9... | None | ||
| 11 | CC12C=CC(=O)C=C1C(O)CC1C2C(=O)CC2(C)C1CCC2(O)C... | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.781 | 0.710 | [24, 18, 17, 16, 15, 14] | P45011B12m_LR | 11docrtsl | crtsl | 6 | P45011B12m | ... | 111.90 | C21H26O6 | True | True | nan | 1.0 | 374.1729:78.4197;375.1763:18.2252;376.1797:2.9... | None | ||
| 12 | CC12C=CC(=O)C=C1CCC1C2C(=O)C(O)C2(C)C1CCC2(O)C... | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.781 | 0.702 | [0, 9, 11, 12, 14, 15] | P45011B12m_LR | 11docrtsl | crtsl | 6 | P45011B12m | ... | 111.90 | C21H26O6 | True | True | nan | 1.0 | 374.1729:78.4197;375.1763:18.2252;376.1797:2.9... | None | ||
| 13 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(CO)C1CCC2(O)C(=... | NC(=O)c1ccc[n+](C2OC(COP(=O)([O-])OP(=O)([O-])... | 0.617 | 0.625 | [15, 14, 12, 11, 9, 10, 3, 2, 1, 0] | HMR_2010_LR | crtstrn | M00429 | 10 | HMR_2010 | ... | 111.90 | C21H26O6 | True | True | nan | 1.0 | 374.1729:78.4197;375.1763:18.2252;376.1797:2.9... | None | ||
| 14 | CC12C=CC(=O)C=C1CCC1C2C(=O)CC2(C)C1CCC2(OC1OC(... | O=c1ccn(C2OC(COP(=O)([O-])OP(=O)([O-])[O-])C(O... | 0.362 | 0.673 | [24, 18, 17, 16, 15, 14, 12, 11, 9, 10, 3, 4, ... | UGT1A9r_LR | 5adtststerone | 5adtststeroneglc | 15 | UGT1A9r | ... | 187.89 | C27H34O11 | False | False | nan | 1.0 | 534.2101:72.6213;535.2135:21.7955;536.2168:4.7... | None |
15 rows × 39 columns
Molecular classification
Classify molecules based on their SMILES strings.
This function submits a query to the ClassyFire web service and returns a data frame with the classification results. This function sends an online request to the ClassyFire server in order to conduct the search. When performing this task, make sure you have an internet connection.
[27]:
classification=classify_molecules(masses,smiles_col='main_product_smiles',names_col='metabolite_id')
classification
Display molecules and data
This function displays a grid of molecules from a data frame, using different colors to indicate the values of a specified column.
[26]:
display_molecules(masses,columns_to_display=['reaction_id','PubChem_CID',"origin","Lipinski","Veber","Brenk"])#,'kingdom','superclass','class','direct_parent','description'])
[26]:
[ ]: